Introducción
Mundo oculto
A primera vista, los archivos digitales se nos presentan como iconos familiares con nombres descriptivos: un documento de texto, una imagen, un vídeo, un ejecutable, etc. Sin embargo, lo que vemos en la interfaz gráfica del sistema operativo es solo una representación superficial. Detrás de cada archivo hay un mundo oculto compuesto por secuencias de bytes organizadas según un patrón específico. Esta estructura interna, invisible a simple vista, es la clave para entender cómo se almacenan, interpretan y manipulan los datos en el nivel más bajo del sistema.
Cada tipo de archivo —ya sea un PDF, un JPG o un MP3— posee una firma interna que lo define, generalmente ubicada al principio (cabecera) y, en algunos casos, también al final (cola) del archivo. Estas marcas permiten a los programas y al sistema operativo reconocer qué tipo de datos contiene un archivo y cómo deben ser procesados. Así, incluso si se cambia la extensión de un archivo manualmente, su contenido real puede delatar su verdadera naturaleza.
Comprender esta estructura no solo es una cuestión académica o técnica: tiene aplicaciones prácticas fundamentales. En análisis forense digital, por ejemplo, permite descubrir archivos que han sido renombrados o camuflados. En recuperación de datos, facilita la identificación de fragmentos válidos de archivos dañados o borrados. En ciberseguridad, ayuda a detectar software malicioso que se esconde bajo apariencias inofensivas.
En definitiva, adentrarse en el análisis binario es como mirar más allá del velo gráfico del sistema: nos permite descubrir la verdadera naturaleza de los archivos, entender cómo están construidos y, lo más importante, manipularlos con conocimiento de causa.
¿Qué es un editor hexadecimal?
Un editor hexadecimal (también conocido como hex editor) es una herramienta diseñada para visualizar y modificar el contenido interno de un archivo a nivel de byte. Su función principal es mostrar los datos binarios que conforman cualquier archivo, pero lo hace de una forma más accesible para el ser humano: en formato hexadecimal (base 16) acompañado, en muchos casos, por una interpretación en ASCII.
La vista típica de un editor hexadecimal se organiza en tres columnas: la primera muestra la posición del byte dentro del archivo (offset), la segunda presenta los valores hexadecimales de los bytes, y la tercera intenta traducir esos valores a caracteres legibles si es posible. Esta representación permite identificar fácilmente patrones, cabeceras, colas, secuencias repetidas o incluso fragmentos ocultos de información.
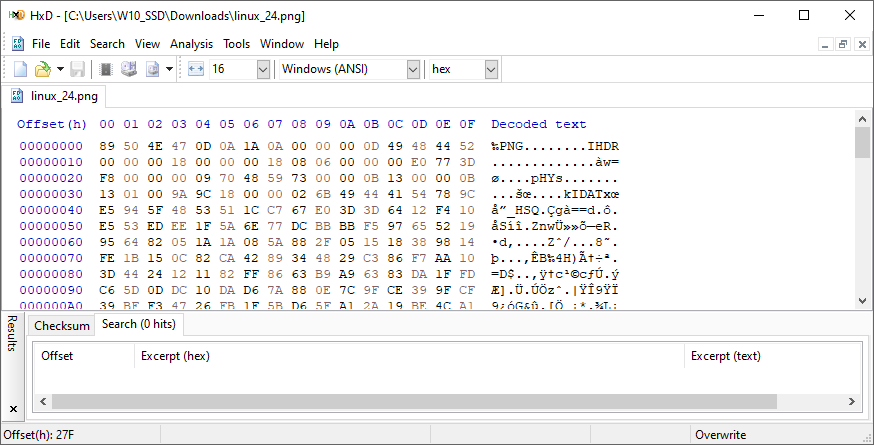
Los editores hexadecimales son herramientas imprescindibles en campos como el análisis forense digital, la ingeniería inversa, la recuperación de datos y el desarrollo de software de bajo nivel. Su precisión y capacidad para editar archivos byte a byte los convierte en aliados poderosos cuando se requiere un control total sobre la estructura interna de los datos.
Algunos editores hexadecimales populares son:
- HxD (gratuito, Windows): ligero, intuitivo y muy usado tanto en entornos educativos como profesionales.
- 010 Editor (de pago, multiplataforma): avanzado, con soporte para plantillas binarias que permiten interpretar estructuras complejas.
- Hex Fiend (gratuito, macOS): rápido y optimizado para manejar archivos grandes en sistemas Apple.
- WinHex (gratuita limitada y de pago, Windows): orientado a análisis forense y recuperación de datos.
- Hexyl Hex Editor (gratuito, multiplataforma): capaz de editar archivos binarios en formato hexadecimal, la búsqueda y reemplazo de contenido, la edición de bloques de memoria, y la gestión de archivos grandes.
- UltraEdit (de pago, multiplataforma): editor de texto poderoso y versátil que ofrece una amplia gama de funciones, incluyendo resaltado de sintaxis, plegado de código, soporte Unicode, editor hexadecimal, cliente FTP, consola SSH/Telnet, búsqueda y reemplazo, macros y scripting, y edición en modo columna/bloque.
La Clave de la Identificación: Cabeceras y Colas
El proceso de reconocimiento binario de archivos se basa principalmente en la detección y análisis de las cabeceras (headers) y colas (footers) que forman parte del propio contenido del archivo. Estos elementos funcionan como “marcas de identidad” o «magic bytes» que permiten distinguir de manera inequívoca el tipo y la estructura del archivo.
Cabeceras (Headers)
La cabecera de un archivo es una secuencia de bytes situada en los primeros bytes del fichero. Su función principal es identificar el tipo de archivo, así como aportar información adicional relevante sobre su contenido y formato. La mayoría de los formatos estándar incorporan una cabecera única, conocida como número mágico (magic number), que suele ser suficiente para su reconocimiento.
Características principales:
- Ubicación: Siempre al comienzo del archivo (offset 0).
- Tamaño: Varía según el formato; puede ser de 2, 4, 8 bytes o más.
- Contenido: Incluye identificadores únicos (magic numbers), versiones de formato, y en ocasiones información como tamaño total, codificación, etc.
- Ejemplo:
- PDF: Los archivos PDF comienzan con la cadena ASCII
%PDF-(hexadecimal:25 50 44 46 2D). - PNG: Los archivos PNG inician con
89 50 4E 47 0D 0A 1A 0A. - ZIP: La secuencia de cabecera típica es
50 4B 03 04.
- PDF: Los archivos PDF comienzan con la cadena ASCII
La detección de estos patrones permite identificar el archivo aunque la extensión haya sido cambiada o eliminada.
Colas (Footers)
La cola de un archivo es una secuencia de bytes situada al final del fichero, que cumple distintas funciones según el formato:
- Delimitación: Marca el final de los datos útiles del archivo.
- Integridad: Puede incluir sumas de comprobación o hashes para verificar la integridad del contenido.
- Identificación: Algunos formatos la utilizan como marca de cierre, reforzando la identificación del tipo de archivo y permitiendo validar si el archivo está completo.
Características principales:
- Ubicación: Siempre al final del archivo.
- Tamaño: Generalmente fija, pero depende del formato.
- Contenido: Puede ser una cadena fija, un bloque de control o valores de verificación.
- Ejemplo:
- JPEG: Finaliza con
FF D9. - PDF: Termina con la cadena
%%EOF. - PNG: Acaba con el bloque
IEND(49 45 4E 44 AE 42 60 82en hexadecimal).
- JPEG: Finaliza con
Relación entre cabecera y cola
En muchos formatos, la presencia simultánea de la cabecera y la cola esperadas garantiza que el archivo es del tipo declarado y que, además, no está truncado o corrupto. Este doble chequeo es habitual en utilidades de recuperación de datos y en análisis forense, donde es frecuente trabajar con archivos fragmentados o renombrados.
Fundamentos Teóricos
Representación Binaria y Hexadecimal
La representación binaria y la representación hexadecimal son dos sistemas numéricos fundamentales en informática y electrónica, especialmente relevantes en el análisis de archivos a bajo nivel.
La representación binaria utiliza únicamente dos símbolos, 0 y 1, para expresar cualquier cantidad. Cada dígito binario se denomina bit (binary digit), y ocho bits forman un byte. En el contexto de archivos, todos los datos —ya sean texto, imágenes o programas— se almacenan y transmiten en secuencias de bits. Por ejemplo, el número decimal 13 se representa en binario como 1101.
La representación hexadecimal, por su parte, es un sistema de base 16 que utiliza los dígitos del 0 al 9 y las letras A a F (o a–f) para los valores del 10 al 15. Su principal utilidad radica en que cada dígito hexadecimal equivale exactamente a cuatro bits, lo que simplifica la lectura y el análisis de grandes cadenas de datos binarios. Por ejemplo, el número decimal 222 en binario se representa como 1101 1110 y en hexadecimal como DE.
Ambos sistemas se emplean habitualmente para visualizar y analizar archivos en programas de edición hexadecimal donde cada byte del archivo se representa como dos dígitos hexadecimales. Esto facilita la identificación de cabeceras, colas y patrones binarios, permitiéndonos interpretar con mayor rapidez la estructura interna de cualquier archivo.
Orden de los bytes
El término endianness (orden de los bytes) describe la forma en que los sistemas informáticos almacenan y representan los bytes de un número multibyte (por ejemplo, de 16, 32 o 64 bits) en memoria o en archivos binarios. El endianness afecta directamente a la interpretación de los datos, ya que distintos sistemas pueden usar diferentes órdenes de almacenamiento.
Existen principalmente dos formatos:
- Big-endian: El byte más significativo (MSB, Most Significant Byte) se almacena primero (en la posición de menor dirección de memoria o offset 0). Es decir, el valor se guarda «de izquierda a derecha», tal y como lo escribiríamos en notación habitual.
- Little-endian: El byte menos significativo (LSB, Least Significant Byte) se almacena primero. Es decir, los bytes se almacenan «al revés», comenzando por el valor de menor peso.
La elección de uno u otro formato depende de la arquitectura del procesador o del estándar del archivo, y es fundamental para interpretar correctamente los datos binarios. Determinar si un archivo almacena datos en formato LSB (Little-Endian) o MSB (Big-Endian) no siempre es inmediato, ya que depende tanto del tipo de archivo como de su especificación. Sin embargo, existen métodos y buenas prácticas para averiguarlo.
Consultar la Especificación del Formato
La manera más fiable es revisar la documentación oficial del formato de archivo. Por ejemplo:
- BMP, WAV, PCAP (Windows): suelen ser Little-Endian.
- TIFF: puede ser Little o Big Endian; la cabecera indica el endianness.
- PNG, ZIP: en general, los campos multibyte son Big-Endian.
- Formato propio o desconocido: puede requerir análisis manual.
Inspección de la Cabecera
Algunos archivos incluyen una firma o campo específico que indica explícitamente el endianness.
Ejemplo:
- TIFF:
- Si empieza por
"II"(49 49hex), es Little-Endian («Intel»). - Si empieza por
"MM"(4D 4Dhex), es Big-Endian («Motorola»).
- Si empieza por
- WAV (RIFF):
- Siempre utiliza Little-Endian para los campos numéricos multibyte.
Interpretación de Valores Conocidos
Si el formato no lo especifica claramente, puedes buscar un campo cuyo valor conozcas (por ejemplo, el ancho de una imagen o una versión conocida) y comparar su representación binaria:
- Si ves, por ejemplo, los bytes
{00 01}y sabes que el valor debería ser 1, probablemente sea Big-Endian. - Si ves
{01 00}para el mismo valor, es Little-Endian.
Herramientas de Análisis
Utiliza editores hexadecimales o librerías de análisis forense que reconozcan el formato y, en muchos casos, indiquen automáticamente el endianness.
Estructura General de un Archivo
Desde el punto de vista técnico, un archivo es una secuencia lineal de bytes cuya organización interna responde a las especificaciones de su formato. Esta estructura suele dividirse en tres grandes segmentos: cabecera (header), cuerpo de datos (data segment) y, en ciertos casos, cola (footer).
La cabecera ocupa los primeros bytes del archivo (generalmente en el offset 0) y tiene una función descriptiva y estructural. Suele incluir un número mágico o identificador único, seguido de metadatos como versión del formato, tamaño total, información sobre codificación, descriptores de bloques, offsets hacia otras partes internas, o estructuras de control. Su tamaño es fijo en algunos formatos (por ejemplo, 44 bytes en WAV) y variable en otros, donde puede adaptarse a las necesidades del archivo.
Tras la cabecera se encuentra el bloque principal, que almacena la información útil del archivo. La interpretación de estos datos depende íntegramente de lo declarado en la cabecera. Por ejemplo, en imágenes BMP, el cuerpo de datos almacena los valores RGB de cada píxel; en archivos ejecutables PE (Portable Executable), incluye secciones como .text, .data, .rdata, etc.; en archivos comprimidos, contiene los flujos de datos codificados. El formato del bloque de datos puede incluir, a su vez, subcabeceras, estructuras anidadas, punteros internos y delimitadores de bloques, según la complejidad del archivo.
No todos los formatos implementan una cola, pero cuando existe, su finalidad es proporcionar un delimitador de cierre, mecanismos de control de integridad (checksums, hashes), o información adicional necesaria para la lectura inversa o la validación completa del archivo. Ejemplos de colas técnicas incluyen la marca FF D9 al final de archivos JPEG, el registro End of Central Directory en ZIP (50 4B 05 06), o los bloques IEND en PNG. Como ejemplo contrapuesto tenemos los archivos BMP, los cuales no tienen definidos bytes de cola aunque esto no es problema ya que tras los bytes de la cabecera tenemos los bytes del tamaño del archivo.
Ejemplo 1: Estructura binaria de un archivo PNG
Un archivo PNG (Portable Network Graphics) sigue una estructura perfectamente definida, compuesta por una firma inicial y una secuencia de bloques denominados chunks.
Estructura general de un PNG
- Firma PNG
Los primeros 8 bytes constituyen la firma del formato PNG:
Hexadecimal:89 50 4E 47 0D 0A 1A 0A
Esta cabecera permite descartar archivos corruptos o de otro tipo. - Bloques o Chunks
Tras la firma, el archivo está compuesto por una serie de chunks. Cada chunk tiene la siguiente estructura:- Length (4 bytes): Longitud del campo de datos del chunk.Chunk Type (4 bytes): Identificador ASCII (por ejemplo,
IHDR,IDAT,IEND).Chunk Data (variable): Datos del chunk.CRC (4 bytes): Checksum CRC32 para comprobar la integridad.
Los chunks obligatorios más relevantes son:- IHDR (Header): Define ancho, alto, profundidad de color, tipo de color, compresión, filtro y entrelazado.
- IDAT (Image Data): Contiene los datos comprimidos de la imagen (puede haber varios).
- IEND (End): Marca el final del archivo.
- Length (4 bytes): Longitud del campo de datos del chunk.Chunk Type (4 bytes): Identificador ASCII (por ejemplo,
Ejemplo en bytes (inicio y final de un PNG)
89 50 4E 47 0D 0A 1A 0A # Firma PNG
00 00 00 0D 49 48 44 52 ... # IHDR (tamaño, color, etc.)
... # Chunks de metadatos opcionales (tEXt, pHYs, etc.)
... # Uno o varios bloques IDAT (datos de imagen)
49 45 4E 44 AE 42 60 82 # IEND (marca de fin)Ejemplo 2: Estructura binaria de un archivo BMP
El formato BMP (Bitmap) es un formato gráfico simple pero ampliamente utilizado en entornos Windows. Su estructura consta de varias cabeceras y el bloque de datos de la imagen.
Estructura general de un BMP (BMP clásico 24 bits)
- Bitmap File Header
- 2 bytes: Identificador (siempre
42 4D, es decir, «BM» en ASCII). - 4 bytes: Tamaño total del archivo.
- 2 bytes: Reservado.
- 2 bytes: Reservado.
- 4 bytes: Offset donde comienzan los datos de imagen.
- 2 bytes: Identificador (siempre
- DIB Header (BITMAPINFOHEADER)
- 4 bytes: Tamaño de esta cabecera (normalmente 40).
- 4 bytes: Ancho de la imagen.
- 4 bytes: Alto de la imagen.
- 2 bytes: Número de planos (siempre 1).
- 2 bytes: Profundidad de color (bits por píxel, por ejemplo, 24).
- 4 bytes: Tipo de compresión.
- 4 bytes: Tamaño de los datos de imagen.
- 4 bytes: Resolución horizontal.
- 4 bytes: Resolución vertical.
- 4 bytes: Número de colores en la paleta.
- 4 bytes: Colores importantes.
- Paleta de colores (solo en BMP de menos de 16 bits por píxel):
Array de estructuras RGBQUAD, opcional según el modo de color. - Datos de imagen (Pixel Array)
Datos de píxeles en formato BGR (no RGB), alineados en múltiplos de 4 bytes por fila.
42 4D # "BM" (cabecera)
46 1C 00 00 # Tamaño del archivo (ejemplo)
00 00 # Reservado
00 00 # Reservado
36 00 00 00 # Offset a los datos de píxeles
28 00 00 00 # Tamaño del DIB header (40 bytes)
20 03 00 00 # Ancho (800)
58 02 00 00 # Alto (600)
01 00 # Planos
18 00 # 24 bits por píxel
00 00 00 00 # Sin compresión
10 1C 00 00 # Tamaño del array de píxeles
...Limitaciones del Análisis de Cabeceras y Colas
Si bien el análisis de cabeceras y, en menor medida, de colas es una técnica fundamental y a menudo muy efectiva para una rápida identificación del tipo de archivo, es crucial comprender que no es infalible y presenta ciertas limitaciones significativas. Confiar ciegamente en este método puede llevar a conclusiones erróneas o a pasar por alto información vital. A continuación, detallamos las principales limitaciones:
- Ausencia de firmas claras o estandarizadas: No todos los tipos de archivo poseen una «firma mágica» bien definida al inicio o un «footer» característico al final. Archivos de texto plano (.txt, .csv sin cabecera específica), scripts sin shebang, o formatos de datos crudos y personalizados pueden carecer de estos identificadores. En estos casos, el análisis de cabeceras y colas resulta inútil para la identificación.
- Archivos corruptos o dañados: Si un archivo está dañado, es posible que su cabecera o cola estén alteradas, incompletas o ausentes. Un editor hexadecimal mostrará los bytes, pero la secuencia esperada podría no estar presente, llevando a una identificación incorrecta o a la incapacidad de identificar el archivo, aunque el resto de su contenido pueda ser parcialmente recuperable.
- Firmas mágicas ambiguas o compartidas: Aunque es raro para formatos bien establecidos, teóricamente es posible que secuencias de bytes muy cortas y genéricas puedan aparecer casualmente al inicio de archivos de diferente naturaleza, o que formatos menos comunes o antiguos compartan firmas similares. Esto podría llevar a una clasificación errónea si no se complementa con otros análisis.
- Archivos cifrados o comprimidos (Contenedores): Cuando un archivo está cifrado o completamente contenido dentro de un archivo comprimido (como un ZIP o RAR), la cabecera que se observará será la del algoritmo de cifrado o la del formato contenedor, no la del archivo original. Para identificar el contenido real, primero se necesitaría descifrar o descomprimir los datos. Por ejemplo, un documento Word (.docx) es en realidad un archivo ZIP; su cabecera será PK, no la de un documento Word tradicional.
- Suplantación o modificación intencionada (Spoofing): Un actor malicioso puede modificar deliberadamente la cabecera de un archivo para hacerlo pasar por otro tipo (por ejemplo, cambiar la cabecera de un ejecutable malicioso para que parezca una imagen). Esto se usa para evadir sistemas de detección basados únicamente en firmas o para engañar a los usuarios. Si bien el resto de la estructura del archivo no coincidirá, un análisis superficial de la cabecera podría ser engañado.
- Archivos embebidos o contenedores complejos: Muchos formatos de archivo modernos son, en realidad, contenedores que albergan múltiples flujos de datos o archivos (por ejemplo, OLE en documentos de Microsoft Office antiguos, o el mencionado formato DOCX). El análisis de la cabecera principal solo identifica el contenedor, no necesariamente todos los tipos de datos que residen en su interior. La esteganografía también oculta archivos dentro de otros, donde la cabecera del archivo portador es la única visible inicialmente.
- Información limitada: La cabecera identifica el tipo de archivo, pero generalmente no ofrece información sobre la validez del contenido, la versión específica del formato (a menos que esté incluida en la firma), metadatos detallados o si el archivo está completo. Un archivo puede tener la cabecera correcta de un JPEG, pero estar truncado o corrupto internamente.
- Formatos propietarios o no documentados: Existen innumerables formatos de archivo propietarios o aquellos utilizados por software especializado que no tienen firmas mágicas públicamente documentadas. Identificar estos archivos mediante análisis de cabeceras es prácticamente imposible sin conocimiento previo o ingeniería inversa del formato.
- Variaciones dentro del mismo tipo de archivo: Algunos formatos pueden tener ligeras variaciones en sus cabeceras dependiendo de la sub-versión, las características habilitadas o el software que los creó. Un análisis que busque una única firma exacta podría fallar al identificar variantes legítimas del mismo tipo de archivo.
Si bien el análisis de cabeceras y colas es un primer paso esencial y a menudo suficiente para una categorización inicial, un analista experto o un software de DFI (Digital Forensics and Incident Response) robusto combinará esta técnica con otras, como el análisis de la estructura interna del archivo, la extracción de cadenas de texto (strings), el análisis de entropía, y la comparación con bases de datos de formatos más extensas para obtener una identificación más fiable y completa. Estas limitaciones subrayan la necesidad de un enfoque multifacético en el reconocimiento de archivos.
Magic bytes
A continuación, se presenta una tabla con algunas de las firmas mágicas más comunes y reconocibles. Es importante notar que algunos formatos pueden tener múltiples firmas o variaciones dependiendo de la sub-versión o características específicas.
| Tipo de Archivo | Extensión(es) Común(es) | Magic bytes (Hex) | Magic bytes (ASCII) | Desplazamiento (Offset) | Notas |
| Imágenes | |||||
| JPEG / JPG Image | .jpg, .jpeg | FF D8 FF E0 xx xx 4A 46 49 46 00 | ÿØÿà..JFIF. | 0 | La xx xx es la longitud. También común: FF D8 FF E1 (EXIF), FF D8 FF DB (sin APP0/APP1) |
| PNG Image | .png | 89 50 4E 47 0D 0A 1A 0A | .PNG…. | 0 | |
| GIF Image | .gif | 47 49 46 38 37 61 o 47 49 46 38 39 61 | GIF87a o GIF89a | 0 | Corresponde a las versiones GIF87a y GIF89a. |
| BMP Image (Bitmap) | .bmp | 42 4D | BM | 0 | |
| TIFF Image | .tif, .tiff | 49 49 2A 00 (Little-Endian) o 4D 4D 00 2A (Big-Endian) | II*. o MM.* | 0 | El orden de bytes (Intel o Motorola) se indica en la firma. |
| WebP Image | .webp | 52 49 46 46 xx xx xx xx 57 45 42 50 | RIFF….WEBP | 0 | xx xx xx xx es el tamaño del chunk. |
| Documentos | |||||
| PDF Document | 25 50 44 46 | 0 | Usualmente seguido por la versión, ej. %PDF-1.7. | ||
| Microsoft Office (OLE) | .doc, .xls, .ppt | D0 CF 11 E0 A1 B1 1A E1 | ÐÏ.ࡱ.á | 0 | Formato de almacenamiento estructurado OLE2, usado por versiones antiguas de Office. |
| Microsoft Office (OOXML) | .docx, .xlsx, .pptx | 50 4B 03 04 | PK.. | 0 | Estos son en realidad archivos ZIP. La firma es la de un archivo ZIP. |
| Rich Text Format | .rtf | 7B 5C 72 74 66 31 | {\rtf1 | 0 | |
| Archivos Comprimidos | |||||
| ZIP Archive | .zip | 50 4B 03 04 | PK.. | 0 | La firma PK proviene de Phil Katz, el creador del formato. |
| RAR Archive | .rar | 52 61 72 21 1A 07 00 (v1.5-4.0) o 52 61 72 21 1A 07 01 00 (v5.0+) | Rar!…. | 0 | |
| GZIP Archive | .gz, .tgz | 1F 8B | .. | 0 | |
| 7-Zip Archive | .7z | 37 7A BC AF 27 1C | 7z¼¯’. | 0 | |
| TAR Archive | .tar | 75 73 74 61 72 00 30 30 (ustar) | ustar.00 | 257 | ¡Ojo! No siempre al inicio. Esta es la firma POSIX ustar. Puede haber otras variaciones. |
| Ejecutables y Librerías | |||||
| Windows PE Executable | .exe, .dll, .sys | 4D 5A | MZ | 0 | Iniciales de Mark Zbikowski. Seguido por más estructura PE. |
| ELF Executable (Linux) | (varias) | 7F 45 4C 46 | .ELF | 0 | Executable and Linkable Format. |
| Mach-O Executable (macOS) | (varias) | FE ED FA CE (32-bit) o FE ED FA CF (64-bit) | þíúÎ o þíúÏ | 0 | Big-Endian. También CE FA ED FE (32-bit LE) y CF FA ED FE (64-bit LE). |
| Java Class File | .class | CA FE BA BE | Êþº¾ | 0 | «Cafe Babe» |
| Dalvik Executable (Android) | .dex | 64 65 78 0A 30 33 35 00 | dex.035. | 0 | |
| Multimedia | |||||
| MP3 Audio (con ID3v2 tag) | .mp3 | 49 44 33 | ID3 | 0 | Si tiene una etiqueta ID3v2 al inicio. Si no, buscar sync frames como FF FB. |
| WAV Audio | .wav | 52 49 46 46 xx xx xx xx 57 41 56 45 | RIFF….WAVE | 0 | xx xx xx xx es el tamaño del chunk. Formato contenedor RIFF. |
| AVI Video | .avi | 52 49 46 46 xx xx xx xx 41 56 49 20 | RIFF….AVI | 0 | xx xx xx xx es el tamaño del chunk. Formato contenedor RIFF. |
| MP4 Video | .mp4, .m4a | Variable, pero a menudo contiene 66 74 79 70 (ftyp) dentro de los primeros bytes (ej. offset 4 si ….ftyp). | ftyp | ~4 | Formato basado en ISO Base Media File Format (ISO/IEC 14496-12). La firma ftyp está en una «caja». |
| FLV (Flash Video) | .flv | 46 4C 56 01 | FLV. | 0 | |
| Otros Formatos | |||||
| SQLite Database | .sqlite, .db | 53 51 4C 69 74 65 20 66 6F 72 6D 61 74 20 33 00 | SQLite format 3. | 0 | |
| Windows Registry File (hive) | .dat, (sin extensión) | 72 65 67 66 | regf | 0 | |
| PostScript Document | .ps, .eps | 25 21 50 53 2D 41 64 6F 62 65 | %!PS-Adobe | 0 | |
| TrueType Font | .ttf | 00 01 00 00 00 | ….. | 0 | |
| OpenType Font | .otf | 4F 54 54 4F 00 | OTTO. | 0 |
Consideraciones Adicionales:
- Longitud Variable: Algunas firmas son cortas (2 bytes para BMP), mientras que otras son más largas (8 bytes para PNG).
- Variaciones: Como se ve en JPEG o GIF, puede haber ligeras variaciones en la firma para indicar sub-tipos o versiones.
- No Universal: No todos los tipos de archivo tienen una firma mágica (ej. archivos de texto plano .txt generalmente no la tienen, a menos que tengan un BOM – Byte Order Mark).
- Herramientas: Comandos como file en Linux/macOS utilizan extensas bases de datos de firmas mágicas (a menudo ubicadas en /usr/share/misc/magic o similar) para identificar archivos. Los editores hexadecimales avanzados también suelen tener la capacidad de interpretar estas firmas.
Conclusiones
El reconocimiento de archivos mediante análisis binario se presenta como una disciplina esencial en campos tan diversos como la informática forense, la seguridad informática, la recuperación de datos y la ingeniería inversa.
A pesar de su potencia, es crucial reconocer que el análisis de cabeceras y colas no es la panacea, por tanto, la precaución dicta que el análisis de magic bytes debe ser un primer paso, complementado idealmente con un examen más profundo de la estructura interna, el análisis de entropía, la extracción de cadenas de texto y otras técnicas heurísticas. Confiar ciegamente en una única firma sin considerar el contexto puede ser arriesgado.
Sé el primero en comentar